FUSE¶

Compare¶
https://www.redhat.com/en/technologies/storage
CEPH: Provides a robust, highly scalable block, object, and filesystem storage platform for modern workloads, like cloud infrastructure and data analytics. Consistently ranked as preferred storage option by OpenStack® users.
Gluster: Provides a scalable, reliable, and cost-effective data management platform, streamlining file and object access across physical, virtual, and cloud environments.
http://cecs.wright.edu/~pmateti/Courses/7370/Lectures/DistFileSys/distributed-fs.html
| |HDFS|iRODS|Ceph|GlusterFS|Lustre| |—|—|—|—|—| |Arch|Central|Central|Distributed|Decentral|Central| |Naming|Index|Database|CRUSH|EHA|Index| |API|CLI, FUSE|CLI, FUSE|FUSE, mount|FUSE, mount|FUSE| |REST|REST| |REST| | | |Fault-detect|Fully connect.|P2P|Fully connect.|Detected|Manually| |sys-avail|No-failover|No-failover|High|High|Failover| |data-aval|Replication|Replication|Replication|RAID-like|No| |Placement|Auto|Manual|Auto|Manual|No| |Replication|Async.|Sync.|Sync.|Sync.|RAID-like| |Cache-cons|WORM, lease|Lock|Lock|No|Lock| |Load-bal|Auto|Manual|Manual|Manual|No|
http://www.youritgoeslinux.com/impl/storage/glustervsceph
Gluster - C¶
software defined distributed storage that can scale to several petabytes.
It provides interfaces for object, block and file storage.
http://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/
Quickstart¶
http://docs.gluster.org/en/latest/Quick-Start-Guide/Quickstart/
gluster peer probe server2 # from server1
gluster peer probe server1 # from server2
# Once this pool has been established, it must be probed from the pool.
gluster peer status
mkdir -p /data/brick1/gv0 # both server1 and server2
gluster volume create gv0 replica 2 server1:/data/brick1/gv0 server2:/data/brick1/gv0 # any server
gluster volume start gv0
gluster volume info
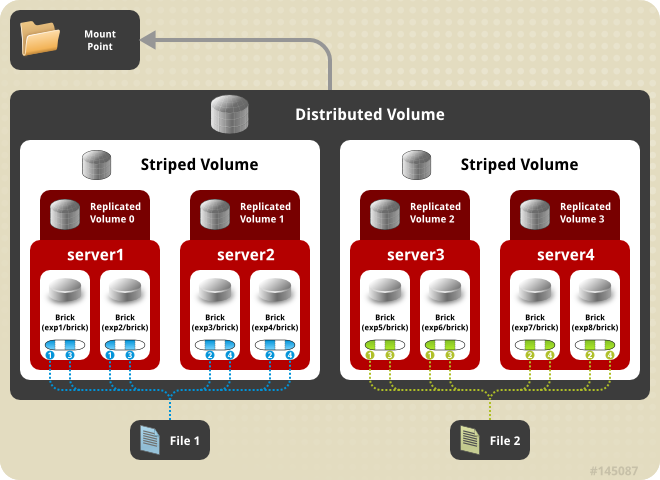
Types of Volumes¶
gluster volume create test-volume \
server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 # Distributed
replica 2 transport tcp server1:/exp1 server2:/exp2 # Replicated, w/ data redundancy
replica 2 transport tcp server1:/exp1 ... server4:/exp4 # R->D

stripe 2 transport tcp server1:/exp1 server2:/exp2 # Striped
stripe 4 transport tcp server1:/exp1 ... server8:/exp8 # S->D

stripe 2 replica 2 transport tcp server1:/exp1 ... server4:/exp4 # R->S (*)
stripe 2 replica 2 transport tcp server1:/exp1 ... server8:/exp8 # R->S->D (*)
(*) only for Map Reduce workloads

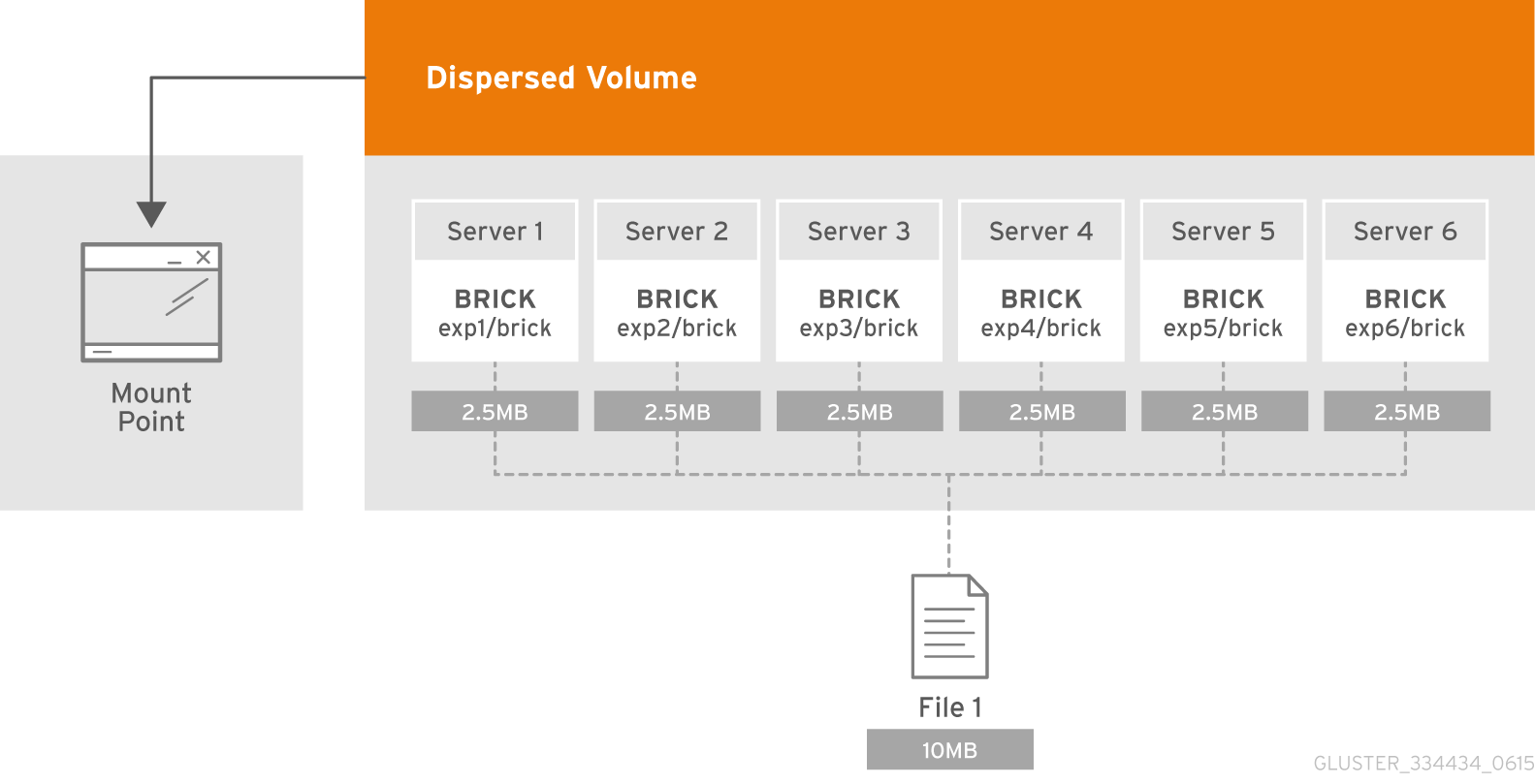
<Dispersed Volume Usable size> = <Brick size> * (#Bricks - Redundancy)
bricks#(>=3) > 2 * redundancy
[disperse [<count>]] [redundancy <count, default=auto>]
disperse 4 server{1..4}:/bricks/test-volume # Dispersed
disperse 3 server1:/brick{1..3} # Dispersed (#)
disperse 3 server1:/brick{1..6} # Distributed Dispersed (#)
(#) on the same server, add `force`
disperse-data 8 redundancy 4 transport tcp
server1:/exp/brick1 server1:/exp/brick2 server1:/exp/brick3 server1:/exp/brick4
server2:/exp/brick1 server2:/exp/brick2 server2:/exp/brick3 server2:/exp/brick4
server3:/exp/brick1 server3:/exp/brick2 server3:/exp/brick3 server3:/exp/brick4
server1:/exp/brick5 server1:/exp/brick6 server1:/exp/brick7 server1:/exp/brick8
server2:/exp/brick5 server2:/exp/brick6 server2:/exp/brick7 server2:/exp/brick8
server3:/exp/brick5 server3:/exp/brick6 server3:/exp/brick7 server3:/exp/brick8
server1:/exp/brick9 server1:/exp/brick10 server1:/exp/brick11 server1:/exp/brick12
server2:/exp/brick9 server2:/exp/brick10 server2:/exp/brick11 server2:/exp/brick12
server3:/exp/brick9 server3:/exp/brick10 server3:/exp/brick11 server3:/exp/brick12

gluster volume info test-volume
gluster volume start test-volume
RDMA(Remote direct memory access)¶
http://docs.gluster.org/en/latest/Administrator%20Guide/RDMA%20Transport/
As of now only FUSE client and gNFS server would support RDMA transport.
Snapshots¶
http://docs.gluster.org/en/latest/Administrator%20Guide/Managing%20Snapshots/
GlusterFS volume snapshot feature is based on thinly provisioned LVM snapshot.
on ZFS¶
http://docs.gluster.org/en/latest/Administrator%20Guide/Gluster%20On%20ZFS/
Ceph - C++¶
Ceph uniquely delivers object, block, and file storage in one unified system.
A Ceph Storage Cluster consists of two types of daemons: * Ceph Monitor: maintains a master copy of the cluster map * Ceph OSD Daemon: checks its own state and the state of other OSDs and reports back to monitors.

Setup¶
http://docs.ceph.com/docs/master/cephfs/
STEP 1: METADATA SERVER
STEP 2: MOUNT CEPHFS
Docker¶
CACHE TIERING¶

Snapshot¶
http://docs.ceph.com/docs/master/rbd/rbd-snapshot/
Ceph supports many higher level interfaces, including QEMU, libvirt, OpenStack and CloudStack.
Ceph supports the ability to create many copy-on-write (COW) clones of a block device shapshot. Snapshot layering enables Ceph block device clients to create images very quickly.
UI - inkscope¶
https://github.com/inkscope/inkscope (with screenshots)

Rook - Go¶
File, Block, and Object Storage Services for your Cloud-Native Environment
https://rook.github.io/docs/rook/master/kubernetes.html 

IPFS¶
combines Kademlia + BitTorrent + Git
mountable filesystem (via FUSE)
http://ipfs.io/<path>
Backup¶
duplicati¶
https://github.com/duplicati/duplicati
https://www.duplicati.com/screenshots/
Store securely encrypted backups in the cloud!
Amazon S3, OneDrive, Google Drive, Rackspace Cloud Files, HubiC, Backblaze (B2), Amazon Cloud Drive (AmzCD), Swift / OpenStack, WebDAV, SSH (SFTP), FTP, and more!